Algoritmos para montagem do genoma
A montagem do genoma é um processo fundamental na bioinformática que envolve a junção dos reads de DNA gerados por tecnologias de sequenciamento (normalmente NGS) no genoma completo do organismo sequenciado. Essa tarefa complexa requer o uso de algoritmos que equilibram eficiência computacional, precisão e escalabilidade. Neste post, exploraremos as duas principais estratégias utilizadas pelos algoritmos de montagem do genoma: a abordagem de Overlap-Layout-Consensus (OLC) e a abordagem baseada em gráficos de de Bruijn.
Estratégia por Overlap-Layout-Consensus (OLC)
A abordagem de Overlap-Layout-Consensus (Sobreposição-Disposição-Consenso) como o nome bem diz, envolve três etapas principais: sobreposição, disposição e consenso.
-
Overlap: Nesta etapa, o algoritmo identifica regiões de similaridade, ou sobreposições, entre os reads que saem do sequenciador. Esta etapa serve para estabelecer a ordem relativa e a orientação dos reads.
-
Layout: Uma vez identificadas as sobreposições, o algoritmo constrói um grafo de disposição no qual os nós representam os reads e as arestas representam as sobreposições, ou seja, os reads são “conectados” pelas sobreposições. O grafo é percorrido para identificar caminhos que correspondem a uma sequência contígua de reads.
-
Consenso: Nesta etapa final, o algoritmo gera uma sequência de consenso para cada disposição, resolvendo discrepâncias e erros presentes nas sobreposições. Isso envolve escolher o nucleotídeo mais provável em cada posição com base no consenso da maioria dos reads e o alinhamento múltiplo.

Esquema do algoritmo OLC
Vantagens e desvantagens do algoritmo OLC
| Vantagens | Desvantagens | |
|---|---|---|
| Precisão ao lidar com regiões repetitivas no genoma. | Intensiva e exigente em memória e poder computacional | |
| Preservação de informações de longo alcance devido ao uso direto das leituras sobrepostas. | OLC pode gerar sequências quiméricas se houver muitos erros de sequenciamento | |
| Bem adequada para montar genomas com cobertura relativamente baixa. | Pode ser incapaz de resolver regiões genômicas muito complexas ou com alta heterozigosidade |
Estratégia por Gráficos de de Bruijn (DBG)
As abordagens baseadas em gráficos de de Bruijn oferecem uma alternativa para a montagem do genoma, particularmente adequada para lidar com reads curtos. as etapas deste algoritmo são as seguintes:
-
K-merização: A primeira etapa envolve quebrar as leituras em k-mers de comprimento k. A escolha de k depende da tecnologia de sequenciamento e das características do genoma que está sendo montado. Um valor de k maior pode reduzir o número de falsas sobreposições, mas também pode aumentar a complexidade do gráfico e exigir mais memória.
-
Construção do Gráfico: Na segunda etapa, um gráfico é construído onde cada k-mer é representado como um nó e as sobreposições entre k-mers são representadas como arestas. O gráfico pode ser construído usando vários métodos, como uma tabela de hash ou uma árvore de sufixos. O gráfico pode ser simplificado removendo k-mers de baixa frequência ou mesclando nós com sequências semelhantes.
-
Travessia do Gráfico: Na terceira etapa, o grafo é percorrido para identificar caminhos que correspondem a uma sequência contígua de k-mers. Os caminhos podem ser montados em sequências mais longas mesclando reads sobrepostos. A diferença do OLC é que o algoritmo DBG representa de forma inteligente as sobreposições (através dos k-mers) para reduzir a complexidade computacional dos reads.
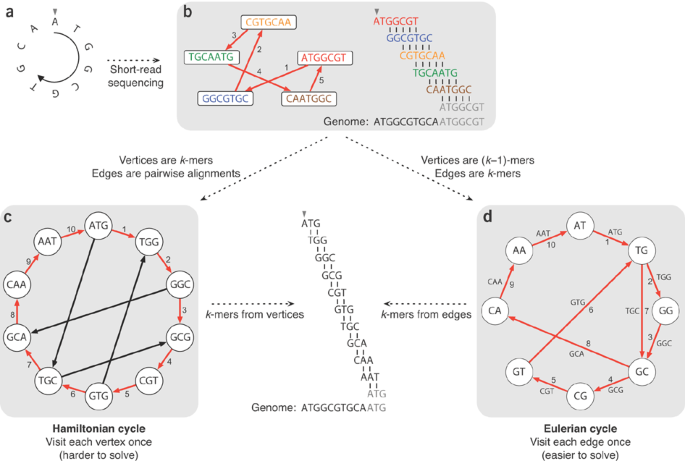
Esquema do algoritmo DBG
Vantagens e desvantagens do algoritmo DBG
| Vantagens | Desvantagens | |
|---|---|---|
| Eficiência em memória devido ao uso de k-mers | Perda de informação devido à fragmentação da informação em k-mers | |
| Ótimo para montagem com fragmentos curtos | Sensível a parâmetros iniciais de montagem, como a escolha de tamanho dos k-mers | |
Conclusões
A montagem do genoma é uma arte complexa que envolve a compreensão do bioinformata a respeito da amostra sequenciada. As duas principais estratégias, a abordagem de OLC e as abordagens baseadas em gráficos de de Bruijn, têm cada uma suas forças e fraquezas. Enquanto a OLC mantém informações de longo alcance e é robusta contra regiões repetitivas, as abordagens baseadas em gráficos de de Bruijn são eficientes em termos de memória e se destacam com leituras curtas de alto rendimento. A escolha entre essas estratégias frequentemente depende das características do genoma a ser montado e dos dados de sequenciamento disponíveis. Avanços nos algoritmos, e o uso de tecnologias de reads longos continuam a refinar e aprimorar ambas as estratégias, contribuindo para nossa compreensão dos genomas dos organismos.