Use bancos de dados e seja mais eficiente

Um dos meus colegas de trabalho está submetendo um projeto de pesquisa, e pediu para que eu lhe enviasse alguns resultados preliminares de uma análise que fiz há alguns meses. O problema: não havia uma maneira simples de agregar toda a informação que ele queria
O motivo desta dificuldade é porque trabalhamos com muitas amostras e sequências. Neste meu projeto atual estou analisando mais de 100 mil plasmídeos, um dataset modesto perto do que outros pesquisadores mais experientes abordam na rotina
Da sequência de DNA destes plasmídeos, foram preditas quase 3 milhões de proteínas, e destas proteínas foram realizadas buscas de HMM contra Pfams, Kofams, NCBIFams e alguns outros perfis. Como o cluster que utilizamos tem tempo máximo de 3 dias para rodar um processo, seria impossível obter os resultados sem antes dividir este dataset em pedaços menores, o que é recomendado para que fosse possível requisitar mais processadores e paralelizar todo o processo.
A resolução gerou outro desafio
Embora tenha sido possível rodar toda esta análise em menos de 2 dias (privilégio de ter acesso a um cluster computacional super poderoso), os resultados ficaram divididos em 528 arquivos tabulares, cada um variando de 200 a 500MB. Concatenar estas tabelas não resolveria muito o problema, porque o custo de memória para abri-las seria muito elevado, mesmo utilizando bibliotecas e programas específicos para isso. Como então analisar este dataset, ou recuperar os resultados específicos que meu colega queria?
528 arquivos tabulares, totalizando 114GB de dados. Zero eficiente
Bancos de dados em arquivo
Em um dos nossos posts mais para frente abordaremos o assunto bancos de dados em mais detalhes, mas o importante é que existem soluções de bancos de dados que são simples arquivos. Exemplos de estruturas como o SQLite permitem uma simplicidade e portabilidade que não podem ser ignorados, ainda mais se o uso dos dados será majoritariamente por um único usuário (no caso eu).
Eu já tinha bastante familiaridade com este tipo de banco de dados, mas foi só quando conversei com este colega que “caiu a ficha” que o meu trabalho estava pouco eficiente. Em algumas horas converti todos estes arquivos em um banco de dados do DuckDB, uma abordagem nova semelhante ao SQLite, mas otimizada para análises científicas. O banco após importar todas as tabelas ficou com apenas 40GB de tamanho, quase um terço do que os arquivos tabulares ocupavam
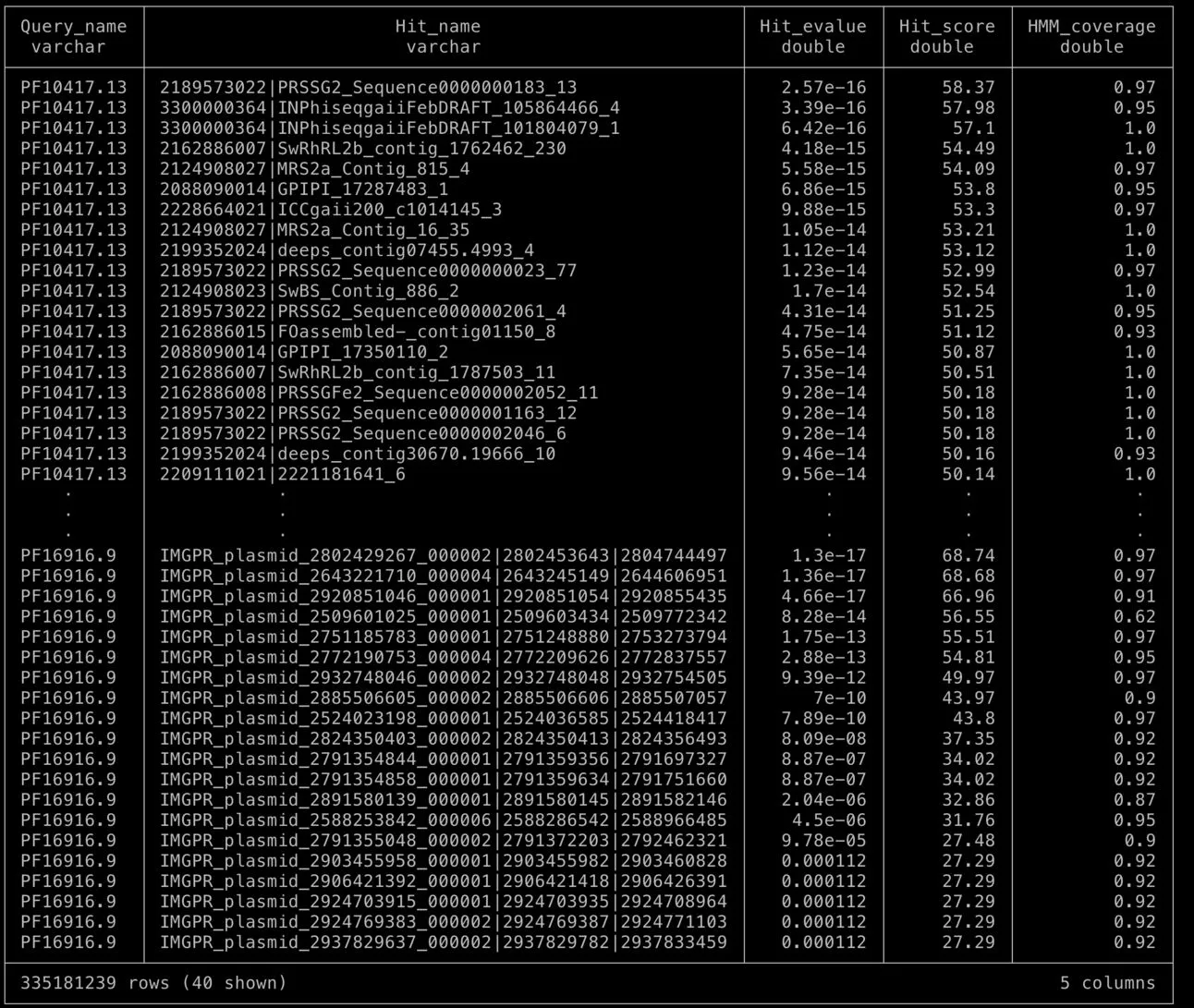
Uma query simples do banco levando poucos segundos e com saída para o terminal, ou redirecionável para um arquivo tabular
Conclusão
Estamos na era do big data e por isso precisamos cada vez mais pensar na eficiência de armazenamento e busca dos dados analisados. O exemplo desta história é na verdade um dado considerado pequeno, mas que pode nos ensinar muito sobre adquirirmos uma “maturidade computacional”. Hoje termos como Data Lake, Data Warehouse, Parquet, Apache Arrow, Spark, são cada vez mais exigências do mercado, e são o próximo degrau após estes bancos de dados mais simples