Predição gênica: desvendando o código genético com ferramentas computacionais

No âmbito da bioinformática e da biologia computacional, a predição de genes é um processo fundamental que nos permite decifrar os mistérios do genoma. Ao empregar algoritmos computacionais e modelos estatísticos, os cientistas conseguem identificar regiões codantes potenciais dentro do DNA dos organismos sequenciados. Neste post de hoje, vamos nos aprofundar nos conceitos subjacentes da predição de genes, explorar o pipeline para abordagens de novo e ab initio e destacar algumas ferramentas populares utilizadas para estas funções.
Entendendo a predição gênica
Os genes servem como unidades funcionais da hereditariedade, contendo as instruções necessárias para a síntese de proteínas. Identificar genes dentro de um genoma é uma tarefa crucial que ajuda os pesquisadores a descobrir os mecanismos moleculares subjacentes a vários processos biológicos. Os métodos computacionais, particularmente os algoritmos de predição de genes, desempenham um papel fundamental neste processo, identificando com precisão e eficiência genes potenciais dentro de sequências genômicas.
Os genomas são vastos e complexos, para eucariotos então mais ainda compreendendo regiões codificantes e não codificantes. As regiões codificantes consistem em exons, que são os segmentos de DNA que são transcritos e eventualmente traduzidos em proteínas. As regiões não codificantes, por outro lado, não codificam proteínas, mas podem desempenhar importantes funções regulatórias dentro dos organismos.
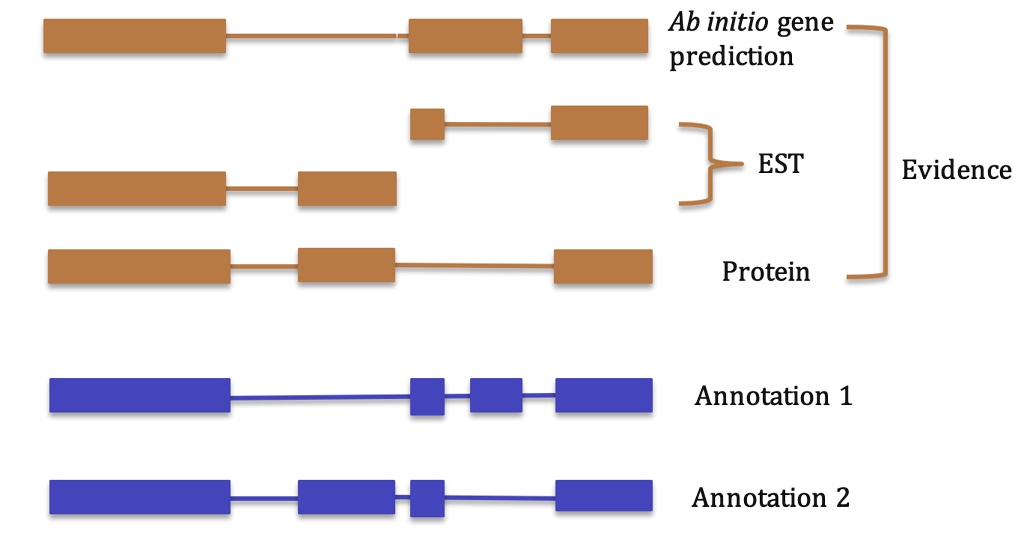
Esquema e desafios da predição gênica
O processo de predição de genes envolve distinguir regiões codificantes de regiões não codificantes e determinar com precisão os limites dos genes. Os algoritmos computacionais utilizam vários modelos estatísticos, técnicas de machine learning e métodos de análise de sequência para atingir esse objetivo.
Predição gênica por similaridade
A busca de genes por similaridade de sequência é uma abordagem conceitualmente simples que se baseia na descoberta de similaridade em sequências de genes entre ESTs (expressed sequence tags), proteínas ou outros genomas comparadas com o genoma de interesse. Essa abordagem é baseada na suposição de que regiões funcionais (exons) são mais conservadas evolutivamente do que regiões não funcionais (regiões intergênicas ou intrônicas). Uma vez que haja semelhança entre uma determinada região genômica e um EST, DNA ou proteína, a informação de similaridade pode ser usada para inferir a estrutura do gene ou a função dessa região. A similaridade de sequência baseada em EST geralmente tem desvantagens, pois os ESTs correspondem apenas a pequenas porções da sequência do gene, o que significa que muitas vezes é difícil prever a estrutura completa do gene de uma determinada região.
Usualmente estas abordagens utilizam alinhamento local e global para estas buscas de similaridade.
Predição gênica ab initio
Para a predição gênica ab initio utiliza a sequência de DNA genômico, que é sistematicamente pesquisada em busca de certos sinais reveladores de genes codificadores de proteínas.
O pipeline para predição de genes ab initio começa com a geração de um conjunto de dados de treinamento. Este conjunto de dados consiste em sequências genômicas com anotações de genes verificadas experimentalmente de organismos relacionados. Essas sequências servem como base para o treinamento de um modelo estatístico que pode prever genes no genoma alvo.
A extração de características é uma etapa crítica na predição de genes ab initio. Vários recursos, como codon bias, presença de códons de início/parada e sinais de sítio de splicing de exon-intron, são extraídos dos dados de treinamento. Esses recursos capturam os atributos estatísticos de genes e regiões não codificantes.
Usando os recursos extraídos, algoritmos de aprendizado de máquina são empregados para treinar o modelo estatístico. O modelo aprende os padrões e as relações estatísticas entre as características e a presença de genes, permitindo fazer previsões precisas.
Depois que o modelo é treinado, ele é aplicado ao genoma alvo para prever as localizações e limites dos genes. As propriedades estatísticas aprendidas com os dados de treinamento guiam as previsões, permitindo a identificação de potenciais regiões codificadoras de proteínas.
Alguns programas para predição gênica
- AUGUSTUS, um preditor gênico ab initio para genomas de eucariotos
- GeneMark, um preditor multiuso que não requer que o usuário crie um conjunto de treinamento
- Prodigal, predição gênica para procariotos
- Glimmer, predição de procariotos e vírus. Há também o GlimmerHMM para eucariotos e Glimmer-MG para metagenomas
Conclusões
A predição gênica é um processo crítico em bioinformática e biologia computacional que permite aos pesquisadores desvendar as complexidades dos genomas. Por meio de diferentes estratégias, juntamente com ferramentas de software sofisticadas, os cientistas podem identificar com precisão genes potenciais, facilitando investigações adicionais sobre as funções e mecanismos desses elementos genéticos.
Vale ressaltar que o desempenho dos métodos de predição dependem em grande parte do conhecimento biológico atual, especialmente o conhecimento no nível molecular da expressão gênica. Portanto, requer grandes esforços de biólogos experimentais e computacionais para tornar a previsão de genes mais precisa, o que pode definitivamente acelerar a descoberta de genes e a mineração de conhecimento. No futuro, com o avanço das técnicas de machine learning a predição de genes pode ser mais precisa e eficiente e depender cada vez menos de dados experimentais prévios.